MIND¶
简介¶
mind召回模型, 在dssm的基础上加入了兴趣聚类功能,支持多兴趣召回,能够显著的提升召回层的效果.
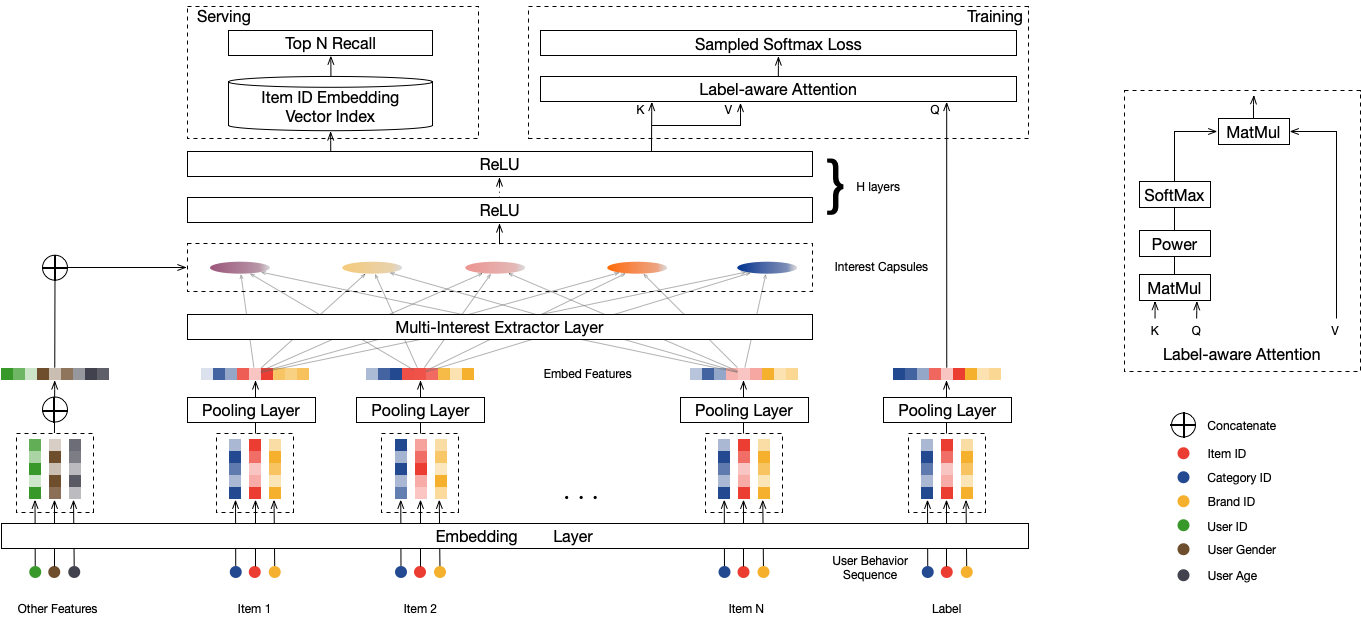
配置说明¶
...
feature_configs {
input_names: "tag_category_list"
feature_type: SequenceFeature
embedding_dim: 16
hash_bucket_size: 1000000
separator: ","
}
feature_configs {
input_names: "tag_brand_list"
feature_type: SequenceFeature
embedding_dim: 16
hash_bucket_size: 1000000
separator: ","
}
feature_configs {
input_names: "seq_ts_gap"
feature_type: SequenceFeature
embedding_dim: 1
hash_bucket_size: 100000
separator: ","
}
model_config:{
model_class: "MIND"
feature_groups: {
group_name: 'hist'
feature_names: 'tag_category_list'
feature_names: 'tag_brand_list'
feature_names: 'seq_ts_gap'
}
feature_groups: {
group_name: 'user'
feature_names: 'user_id'
feature_names: 'cms_segid'
feature_names: 'cms_group_id'
feature_names: 'age_level'
feature_names: 'pvalue_level'
feature_names: 'shopping_level'
feature_names: 'occupation'
feature_names: 'new_user_class_level'
wide_deep:DEEP
}
feature_groups: {
group_name: "item"
feature_names: 'adgroup_id'
feature_names: 'cate_id'
feature_names: 'campaign_id'
feature_names: 'customer'
feature_names: 'brand'
feature_names: 'price'
feature_names: 'pid'
wide_deep:DEEP
}
mind {
user_dnn {
hidden_units: [256, 128, 64, 32]
}
item_dnn {
hidden_units: [256, 128, 64, 32]
use_bn: false
}
concat_dnn {
hidden_units: 64
hidden_units: 32
}
capsule_config {
max_k: 5
max_seq_len: 64
high_dim: 32
squash_pow: 0.2
# use the same numer of capsules for all users
const_caps_num: true
}
simi_pow: 20
l2_regularization: 1e-6
time_id_fea: "seq_ts_gap"
}
embedding_regularization: 5e-5
}
model_class: ‘MIND’, 不需要修改
feature_groups: 需要三个feature_group: hist, user和item, group name不能变
mind: mind相关的参数,必须配置user_dnn和item_dnn
user_dnn: user侧的dnn参数
dnn:
hidden_units: dnn每一层的channel数
use_bn: 是否使用batch_norm, 默认是true
item_dnn: item侧的dnn参数, 配置同user_dnn
note: item侧不能用batch_norm
pre_capsule_dnn: 进入capsule之前的dnn的配置
可选, 配置同user_dnn和item_dnn
concat_dnn: hist seq 和 user feature融合后的dnn
capsule_config: 胶囊(动态路由)的配置
max_k: 胶囊(兴趣)的个数
max_seq_len: hist seq的最大长度
high_dim: 兴趣向量的维度
num_iters: 动态路由(兴趣聚类)的轮数
routing_logits_scale: 放大routing logits, >0时生效;
一些场景显示设置为20时,兴趣向量比较分散, 即相似度比较低(0.8左右)
routing_logits_stddev: routing_logits初始化的标准差
squash_pow: 对squash加的power, 防止squash之后的向量值变得太小
simi_pow: 对相似度做的倍数, 放大interests之间的差异
embedding_regularization: 对embedding部分加regularization,防止overfit
user_seq_combine:
CONCAT: 多个seq之间采取concat的方式融合
SUM: 多个seq之间采取sum的方式融合, default是SUM
time_id_fea: time_id feature的name, 对应feature_config里面定义的特征
注意embedding_dimension必须是1
time_id_fea¶
行为序列特征可以加上time_id, time_id经过1 dimension的embedding后, 在time维度进行softmax, 然后和其它sequence feature的embedding相乘
time_id取值的方式可参考:
训练数据: Math.round((2 * Math.log1p((labelTime - itemTime) / 60.) / Math.log(2.))) + 1
inference: Math.round((2 * Math.log1p((currentTime - itemTime) / 60.) / Math.log(2.))) + 1
此处的时间(labelTime, itemTime, currentTime) 为seconds
调参建议¶
使用增量训练,增量训练可以防止负采样的穿越。
使用HPO对squash_pow[0.1 - 1.0]和simi_pow[10 - 100]进行搜索调优。
要看的指标是召回率,准确率和兴趣损失,三个指标要一起看。
使用全网的点击数据来生成训练样本,全网的行为会更加丰富,这有利于mind模型的训练。
数据清洗:
把那些行为太少的item直接在构造行为序列的时候就挖掉
排除爬虫或者作弊用户
数据采样:
mind模型的训练默认是以点击为目标
如果业务指标是到交易,那么可以对交易的样本重采样
示例Config¶
效果评估¶
离线的效果评估主要看在测试集上的hitrate. 可以参考文档效果评估
评估sql¶
pai -name tensorflow1120_cpu_ext
-Dscript='oss://easyrec/deploy/easy_rec/python/tools/hit_rate_pai.py'
-Dbuckets='oss://easyrec/'
-Darn='acs:ram::xxx:role/aliyunodpspaidefaultrole'
-DossHost='oss-cn-beijing-internal.aliyuncs.com'
-Dtables='odps://pai_rec/tables/mind_item_embedding/dt=${ymd},odps://pai_rec/tables/mind_user_seq_and_embedding/dt=${eval_ymd}'
-Doutputs='odps://pai_rec/tables/mind_hitrate_details/dt=${ymd}/name=mind_top200,odps://pai_rec/tables/mind_total_hitrate/dt=${ymd}/name=mind_top200'
-Dcluster='{
\"ps\" : {
\"count\" : 1,
\"cpu\" : 800,
\"memory\" : 20000
},
\"worker\" : {
\"count\" : 16,
\"cpu\" : 800,
\"memory\" : 20000
}
}'
-DuserDefinedParameters='--recall_type=u2i --top_k=200 --emb_dim=32 --knn_metric=1 --knn_strict=False --batch_size=1024 --num_interests=3';
mind_user_seq_and_embedding:
user_id: string
item_ids: string, “,”分割
user_emb: string, 多个向量之间用”|”分割, 向量内部用”,”分割
user_emb_num: bigint, user兴趣向量的最大个数
说明: 不限制列名的定义,但是限制列的顺序: 0:user_id, 1:item_ids, 2:user_emb, 3:user_emb_num
Local需要修改easy_rec/python/tools/hitrate.py
mind_item_embedding:
item_id: bigint
item_emb: string, item embedding, 向量内部用”,”分割
说明: 不限制列名的定义,但是限制列的顺序: 0:item_id, 1:item_emb
Local可以按照下面的格式准备item embedding数据:
id:int64 feature:string 63133 0.125,0.286,0.913,0.893
num_interests: 最大的兴趣向量数
knn_strict: 是否使用精确的knn计算, 会导致计算量增加
knn_metric: 定义距离计算方式
0: L2 distance
1: Inner Product similarity
emb_dim: user / item表征向量的维度
top_k: knn检索取top_k计算hitrate
recall_type:
u2i: user to item retrieval
评估结果¶
输出下面两张表
mind_hitrate_details:
输出每一个user的hitrate = user_hits / user_recalls
格式如下:
id : bigint topk_ids : string topk_dists : string hitrate : double bad_ids : string bad_dists : string
mind_total_hitrate:
输出平均hitrate = SUM(user_hits) / SUM(user_recalls)
格式如下:
hitrate : double