WideAndDeep¶
简介¶
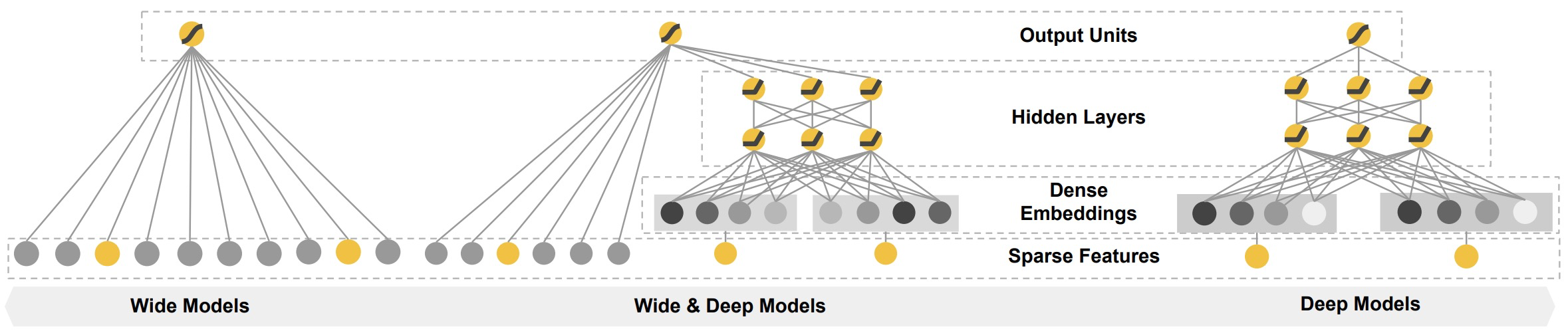
WideAndDeep包含Wide和Deep两部分,Wide部分负责记忆,Deep部分负责泛化。Wide部分可以做显式的特征交叉,Deep部分可以实现隐式自动的特征交叉。
配置说明¶
1. 内置模型¶
model_config:{
model_class: "WideAndDeep"
feature_groups: {
group_name: "deep"
feature_names: "hour"
feature_names: "c1"
...
feature_names: "site_id_app_id"
wide_deep:DEEP
}
feature_groups: {
group_name: "wide"
feature_names: "hour"
feature_names: "c1"
...
feature_names: "c21"
wide_deep:WIDE
}
wide_and_deep {
wide_output_dim: 16
dnn {
hidden_units: [128, 64, 32]
}
final_dnn {
hidden_units: [128, 64]
}
l2_regularization: 1e-5
}
embedding_regularization: 1e-7
}
model_class: ‘WideAndDeep’, 不需要修改
feature_groups:
需要两个feature_group: wide group和deep group, group name不能变
wide_and_deep: wide_and_deep 相关的参数
dnn: deep part的参数配置
hidden_units: dnn每一层的channel数目,即神经元的数目
wide_output_dim: wide部分输出的大小
final_dnn: 整合wide part, deep part的参数输入, 可以选择是否使用
hidden_units: dnn每一层的channel数目,即神经元的数目
embedding_regularization: 对embedding部分加regularization,防止overfit
input_type: 如果在提交到pai-tf集群上面运行,读取MaxCompute 表作为输入数据,data_config:input_type要设置为OdpsInputV2。
2.多优化器(MultiOptimizer)¶
WideAndDeep模型可以配置2个或者3个优化器(optimizer)
配置2个优化器(optimizer), wide参数使用第一个优化器, 其它参数使用第二个优化器
配置3个优化器(optimizer), wide参数使用第一个优化器, deep embedding使用第二个优化器, 其它参数使用第三个优化器
配置实例(2 optimizers, samples/model_config/wide_and_deep_two_opti.config):
optimizer_config: { ftrl_optimizer: { l1_reg: 10 learning_rate: { constant_learning_rate { learning_rate: 0.0005 } } } } optimizer_config { adam_optimizer { learning_rate { constant_learning_rate { learning_rate: 0.0001 } } } }
代码参考: easy_rec/python/model/wide_and_deep.py
WideAndDeep.get_grouped_vars重载了EasyRecModel.get_grouped_vars
3. 组件化模型¶
model_config: {
model_name: 'wide and deep'
model_class: "RankModel"
feature_groups: {
group_name: 'wide'
feature_names: 'user_id'
feature_names: 'movie_id'
feature_names: 'job_id'
feature_names: 'age'
feature_names: 'gender'
feature_names: 'year'
feature_names: 'genres'
wide_deep: WIDE
}
feature_groups: {
group_name: 'deep'
feature_names: 'user_id'
feature_names: 'movie_id'
feature_names: 'job_id'
feature_names: 'age'
feature_names: 'gender'
feature_names: 'year'
feature_names: 'genres'
wide_deep: DEEP
}
backbone {
blocks {
name: 'wide'
inputs {
feature_group_name: 'wide'
}
input_layer {
wide_output_dim: 1
only_output_feature_list: true
}
}
blocks {
name: 'deep_logit'
inputs {
feature_group_name: 'deep'
}
keras_layer {
class_name: 'MLP'
mlp {
hidden_units: [256, 256, 256, 1]
use_final_bn: false
final_activation: 'linear'
}
}
}
blocks {
name: 'final_logit'
inputs {
block_name: 'wide'
input_fn: 'lambda x: tf.add_n(x)'
}
inputs {
block_name: 'deep_logit'
}
merge_inputs_into_list: true
keras_layer {
class_name: 'Add'
}
}
concat_blocks: 'final_logit'
}
model_params {
l2_regularization: 1e-4
}
embedding_regularization: 1e-4
}
model_name: 任意自定义字符串,仅有注释作用
model_class: ‘RankModel’, 不需要修改, 通过组件化方式搭建的单目标排序模型都叫这个名字
feature_groups: 特征组
包含两个feature_group: wide 和 deep group
backbone: 通过组件化的方式搭建的主干网络,参考文档
blocks: 由多个
组件块组成的一个有向无环图(DAG),框架负责按照DAG的拓扑排序执行个组件块关联的代码逻辑,构建TF Graph的一个子图name/inputs: 每个
block有一个唯一的名字(name),并且有一个或多个输入(inputs)和输出input_fn: 配置一个lambda函数对输入做一些简单的变换
input_layer: 对输入的
feature group配置的特征做一些额外的加工,比如执行可选的batch normalization、layer normalization、feature dropout等操作,并且可以指定输出的tensor的格式(2d、3d、list等);参考文档wide_output_dim: wide部分输出的tensor的维度
keras_layer: 加载由
class_name指定的自定义或系统内置的keras layer,执行一段代码逻辑;参考文档concat_blocks: DAG的输出节点由
concat_blocks配置项定义,如果不配置concat_blocks,框架会自动拼接DAG的所有叶子节点并输出。
model_params:
l2_regularization: 对DNN参数的regularization, 减少overfit
embedding_regularization: 对embedding部分加regularization, 减少overfit